



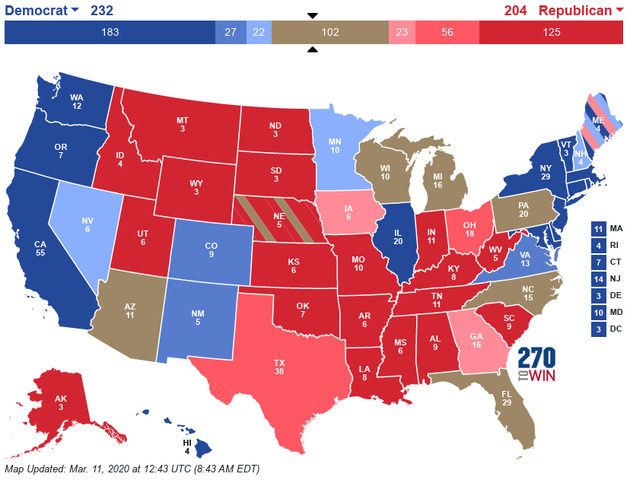
Will the Covid crisis sink Trump?
Submitted by brad on Sun, 2020-03-22 19:44In some discussion, I have seen it become almost an assumption that the economic meltdown and the Covid crisis will erode confidence in the President and settle the election, presuming things continue to November as they likely will. Historical patterns suggest that Presidents with good economies and stock markets get elected, those without them don't. We're seeing economic meltdown, high unemployment, fear and more.
Topic:





 We often repeat the misattributed quote that "for evil to triumph, it is only necessary that good men do nothing." We also often cite father Niemoeller's poem about how "First, they came for the socialists, and I did not speak out -- Because I was not a socialist... Then they came for the Jews ... Then they came for me."
We often repeat the misattributed quote that "for evil to triumph, it is only necessary that good men do nothing." We also often cite father Niemoeller's poem about how "First, they came for the socialists, and I did not speak out -- Because I was not a socialist... Then they came for the Jews ... Then they came for me."