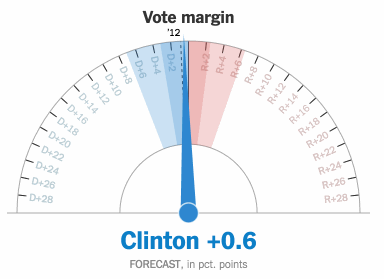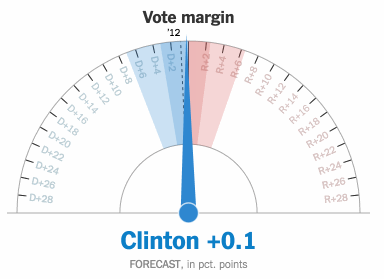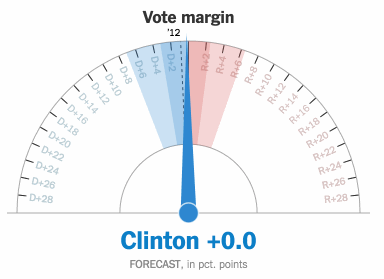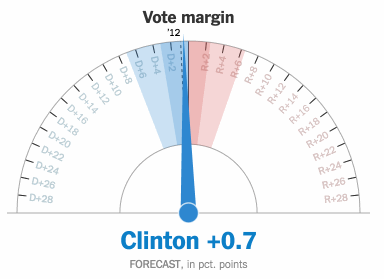
AI is about to change televised sports
Submitted by brad on Sat, 2026-02-21 23:22I don't watch sports live, I watch on a delay. This saves a lot of time immediately by skipping commercials (if I haven't paid to remove them, as I did in the Olympics) but also things like time-outs, long no-action intervals (whistles, pitching changes, etc.) But I also skip far more. The best Winter Olympics sport is curling, for many reasons, but you can watch it in far less time if you are so inclined, without missing the key events. For example, you can usually skip the first few ends, and also the first stones of most ends.