



New Japanese Time -- a radical alternative to Daylight Savings
Submitted by brad on Sun, 2026-03-08 20:07People love and hate Daylight Savings Time. Or more to the point, they hate the transition to and from it, particularly the spring one where you get 1 hour less sleep. It's even been tracked that traffic accidents go up after this shift.
Topic:





 My thought is to combine foveal video with animated avatars for brief moments after
My thought is to combine foveal video with animated avatars for brief moments after 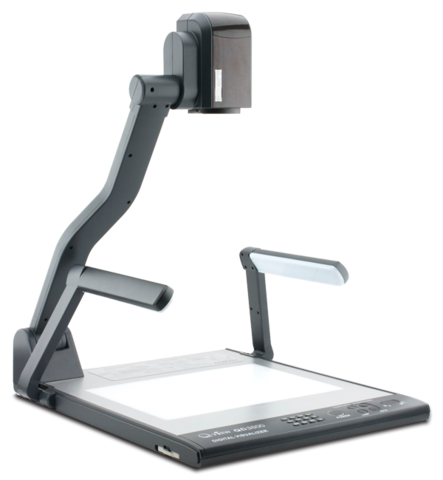 There is no software today that can turn that video into a well scanned document. But there will be. Truth is, we could write it today, but nobody has. If you scan this way, you're making the bet that somebody will. Even if nobody does, you can still go into the video and find any page and pull it out by hand, it will just be a lot of work, and you would only do this for single pages, not for whole documents. You are literally saving the document "for the future" because you are depending on future technology to easily extract it.
There is no software today that can turn that video into a well scanned document. But there will be. Truth is, we could write it today, but nobody has. If you scan this way, you're making the bet that somebody will. Even if nobody does, you can still go into the video and find any page and pull it out by hand, it will just be a lot of work, and you would only do this for single pages, not for whole documents. You are literally saving the document "for the future" because you are depending on future technology to easily extract it.