



Media

Tricks for using Zoom to have a more human connection in large meetings
Submitted by brad on Fri, 2020-05-29 12:15
Topic:
Tags:
Twitter and FB shouldn't ban political ads. They should give them away to registered candidates
Submitted by brad on Wed, 2019-10-30 15:12Twitter's decision to no longer take political advertising is causing a stir, and people are calling on Facebook to do the same. Political advertising isn't just an issue now that we've learned that Russians are doing it to screw with elections. It's the sink for almost all the money spent by campaigns, and thus all the money they raise from donors. The reason that people in office spend more than half their time fundraising is they feel they have no choice.
Topic:
Tabletop Augmented Reality (Tilt5) kickstarter begins today
Submitted by brad on Tue, 2019-09-24 17:19I'm pleased to announce that Tilt5, an augmented reality company for which I am an investor and advisor, has gone live with its kickstarter today.

Topic:
Reflections on 30 years of the dot-com
Submitted by brad on Fri, 2019-06-07 12:20
Tomorrow, June 8, marks the 30th anniversary of my launch of ClariNet.com. In the 1980s, there was a policy forbidding commercial use of the internet backbone, but I wanted to do a business there and found a loophole and got the managers of NSFNet to agree, making ClariNet the first company created to use the internet as a platform, the common meaning of a "dot-com."
Tags:
AR/VR picks up steam again
Submitted by brad on Mon, 2019-06-03 12:29
Topic:
Tags:
Why should first run movies at home cost $3,000?
Submitted by brad on Wed, 2019-04-17 11:45A new service called Red Carpet was announced, which will offer first-run movies in the homes of the very wealthy. You need a $15,000 DRM box and movie rentals are $1,500 to $3,000 per rental. That price is not a typo.
So I wrote an article pondering why that is, and why this could not be done at a price that ordinary people could afford, similar to the price of going to the movies.
Tags:
Review of the LG OLEDs -- it's time for a 4K HDR TV, but it still thinks it's a TV
Submitted by brad on Wed, 2019-04-03 11:12
I recently purchased an LG 4K OLED HDR TV. In spite of the high price, I am pleased with it, and it's made old HDTV look somewhat dull. There is now enough content to upgrade.
Read my review and also my comments on how the TV hasn't yet figured out that many of us just want it for streaming.
Topic:
Tags:
Can phones help older folks enjoy restaurant conversation again?
Submitted by brad on Mon, 2019-04-01 13:06
Topic:
Before the next museum fire, make 4K video of all your documents
Submitted by brad on Fri, 2018-10-05 13:08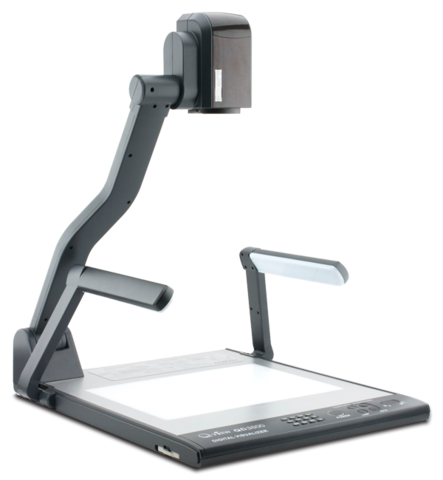
Many of you will have read of the tragic fire which destroyed the National Museum of Brazil. Many of the artifacts and documents in the museum were not photographed or backed up, and so are destroyed forever.
Topic:
Tags:
Is there a limit on how much advertising can make?
Submitted by brad on Tue, 2018-05-29 11:12In my article about how advertising won't pay for robotaxi rides I hinted at one surprise source of the problem. Maybe advertising can never be very valuable.

Right now, the most popular type of advertising, makes about 60 cents for one hour of TV watching. This is with what's known as a $20 CPM (cost per thousand.) Thats 2 cents per ad shown to a person, and an hour of TV has around 15 minutes of ads, or 30 spots.
Topic:
The decline of blogging, and what replaces it?
Submitted by brad on Thu, 2018-04-05 15:37You, by definition, read blog posts. But the era of lots of individual personal web sites seems to be on the wane. It used to be everybody had a "home page" and many had one that updated frequently (a blog) but I, and many other bloggers, have noticed a change of late. It can be seen in the "referer" summaries you get from your web server that show who is making popular links to your site.
Topic:
Olympics Notebook 2018 -- streaming and Curling
Submitted by brad on Sat, 2018-02-17 11:44Every 2 years I watch the Olympics and publish notes on the games, or in particular the coverage. Each time the technology has changed and that alters the coverage.
 This year the big change is much more extensive and refined availability of streaming coverage. Since I desire to "cut the cord" and have no cable or satellite, this has become more important. Unfortunately the story is not all good.
This year the big change is much more extensive and refined availability of streaming coverage. Since I desire to "cut the cord" and have no cable or satellite, this has become more important. Unfortunately the story is not all good.
Topic:
Cloud DVR is not DVR - how to fix that
Submitted by brad on Wed, 2018-01-03 13:52One of the most useful consumer electronic devices of the past two decades is the DVR, pioneered by TiVo. Many people imagined a hard-disk based video recorder before that, but they showed the way.

Topic:
E-mail is more secure than we think, we should use it
Submitted by brad on Thu, 2017-08-17 16:04E-mail is facing a decline. This is something I lament, and I plan to write more about that general problem, but today I want to point out something that is true, but usually not recognized. Namely that E-mail today is often secure in transit, and we can make better use of that and improve it.
The right way to secure any messaging service is end-to-end. That means that only the endpoints -- ie. your mail client -- have the keys and encrypt or decrypt the message. It's impossible, if the crypto works, for anybody along the path, including the operators of the mail servers as well as the pipes, to decode anything but the target address of your message.
We could have built an end-to-end secure E-mail system. I even proposed just how to do it over a decade ago and I still think we should do what I proposed and more. But we didn't.
 Along the way, though, we have mostly secured the individual links an E-mail follows. Most mail servers use encrypted SMTP over TLS when exchanging mail. The major web-mail programs like Gmail use encrypted HTTPS web sessions for reading it. The IMAP and POP servers generally support encrypted connections with clients. My own server supports only IMAPS and never IMAP or POP, and there are others like that.
Along the way, though, we have mostly secured the individual links an E-mail follows. Most mail servers use encrypted SMTP over TLS when exchanging mail. The major web-mail programs like Gmail use encrypted HTTPS web sessions for reading it. The IMAP and POP servers generally support encrypted connections with clients. My own server supports only IMAPS and never IMAP or POP, and there are others like that.
What this means is that if I send a message to you on Gmail, while my SMTP proxy and Google can read that message, nobody tapping the wire can. Governments and possibly attackers can get into those servers and read that E-mail, but it's not an easy thing to do. This is not perfect, but it's actually pretty useful, and could be more useful.
How to do a low bandwidth, retinal resolution video call
Submitted by brad on Sun, 2017-04-23 14:25Not everybody loves video calls, but there are times when they are great. I like them with family, and I try to insist on them when negotiating, because body language is important. So I've watched as we've increased the quality and ease of use.
The ultimate goals would be "retinal" resolution -- where the resolution surpasses your eye -- along with high dynamic range, stereo, light field, telepresence mobility and VR/AR with headset image removal. Eventually we'll be able to make a video call or telepresence experience so good it's a little hard to tell from actually being there. This will affect how much we fly for business meetings, travel inside towns, life for bedridden and low mobility people and more.
Here's a proposal for how to provide that very high or retinal resolution without needing hundreds of megabits of high quality bandwidth.
Many people have observed that the human eye is high resolution on in the center of attention, known as the fovea centralis. If you make a display that's sharp where a person is looking, and blurry out at the edges, the eye won't notice -- until of course it quickly moves to another section of the image and the brain will show you the tunnel vision.
Decades ago, people designing flight simulators combined "gaze tracking," where you spot in real time where a person is looking with the foveal concept so that the simulator only rendered the scene in high resolution where the pilot's eyes were. In those days in particular, rendering a whole immersive scene at high resolution wasn't possible. Even today it's a bit expensive. The trick is you have to be fast -- when the eye darts to a new location, you have to render it at high-res within milliseconds, or we notice. Of course, to an outside viewer, such a system looks crazy, and with today's technology, it's still challenging to make it work.
With a video call, it's even more challenging. If a person moves their eyes (or in AR/VR their head) and you need to get a high resolution stream of the new point of attention, it can take a long time -- perhaps hundreds of milliseconds -- to send that signal to the remote camera, have it adjust the feed, and then get that new feed back to you. There is no way the user will not see their new target as blurry for way too long. While it would still be workable, it will not be comfortable or seem real. For VR video conferencing it's even an issue for people turning their head. For now, to get a high resolution remote VR experience would require sending probably a half-sphere of full resolution video. The delay is probably tolerable if the person wants to turn their head enough to look behind them.
One opposite approach being taken for low bandwidth video is the use of "avatars" -- animated cartoons of the other speaker which are driven by motion capture on the other end. You've seen characters in movies like Sméagol, the blue Na'vi of the movie Avatar and perhaps the young Jeff Bridges (acted by old Jeff Bridges) in Tron: Legacy. Cartoon avatars are preferred because of what we call the Uncanny Valley -- people notice flaws in attempts at total realism and just ignore them in cartoonish renderings. But we are now able to do moderately decent realistic renderings, and this is slowly improving.
 My thought is to combine foveal video with animated avatars for brief moments after saccades and then gently blend them towards the true image when it arrives. Here's how.
My thought is to combine foveal video with animated avatars for brief moments after saccades and then gently blend them towards the true image when it arrives. Here's how.
- The remote camera will send video with increasing resolution towards the foveal attention point. It will also be scanning the entire scene and making a capture of all motion of the face and body, probably with the use of 3D scanning techniques like time-of-flight or structured light. It will also be, in background bandwidth, updating the static model of the people in the scene and the room.
- Upon a saccade, the viewer's display will immediately (within milliseconds) combine the blurry image of the new target with the motion capture data, along with the face model data received, and render a generated view of the new target. It will transmit the new target to the remote.
- The remote, when receiving the new target, will now switch the primary video stream to a foveal density video of it.
- When the new video stream starts arriving, the viewer's display will attempt to blend them, creating a plausible transition between the rendered scene and the real scene, gradually correcting any differences between them until the video is 100% real
- In addition, both systems will be making predictions about what the likely target of next attention is. We tend to focus our eyes on certain places, notably the mouth and eyes, so there are some places that are more likely to be looked at next. Some portion of the spare bandwidth would be allocated to also sending those at higher resolution -- either full resolution if possible, or with better resolution to improve the quality of the animated rendering.
The animated rendering will, today, both be slightly wrong, and also suffer from the uncanny valley problem. My hope is that if this is short lived enough, it will be less noticeable, or not be that bothersome. It will be possible to trade off how long it takes to blend the generated video over to the real video. The longer you take, the less jarring any error correction will be, but the longer the image is "uncanny."
While there are 100 million photoreceptors in the whole eye, but only about a million nerve fibers going out. It would still be expensive to deliver this full resolution in the attention spot and most likely next spots, but it's much less bandwidth than sending the whole scene. Even if full resolution is not delivered, much better resolution can be offered.
Stereo and simulated 3D
You can also do this in stereo to provide 3D. Another interesting approach was done at CMU called pseudo 3D. I recommend you check out the video. This system captures the background and moves the flat head against it as the viewer moves their head. The result looks surprisingly good.
Topic:
Digitizing your papers, literally, for the future, with 4K video
Submitted by brad on Mon, 2017-02-20 15:15I have so much paper that I've been on a slow quest to scan things. So I have high speed scanners and other tools, but it remains a great deal of work to get it done, especially reliably enough that you would throw away the scanned papers. I have done around 10 posts on digitizing and gathered them under that tag.
Recently, I was asked by a friend who could not figure out what to do with the papers of a deceased parent. Scanning them on your own or in scanning shops is time consuming and expensive, so a new thought came to me.
Set up a scanning table by mounting a camera that shoots 4K video looking down on the table. I have tripods that have an arm that extends out but there are many ways to mount it. Light the table brightly, and bring your papers. Then start the 4K video and start slapping the pages down (or pulling them off) as fast as you can.
There is no software today that can turn that video into a well scanned document. But there will be. Truth is, we could write it today, but nobody has. If you scan this way, you're making the bet that somebody will. Even if nobody does, you can still go into the video and find any page and pull it out by hand, it will just be a lot of work, and you would only do this for single pages, not for whole documents. You are literally saving the document "for the future" because you are depending on future technology to easily extract it.
Topic:
Tags:
If you built "Westworld" (or other robot sex) it would probably be with VR
Submitted by brad on Tue, 2016-11-01 16:33HBO released a new version of "Westworld" based on the old movie about a robot-based western theme park. The show hasn't excited me yet -- it repeats many of the old tropes on robots/AI becoming aware -- but I'm interested in the same thing the original talked about -- simulated experiences for entertainment.
The new show misses what's changed since the original. I think it's more likely they will build a world like this with a combination of VR, AI and specialty remotely controlled actuators rather than with independent self-contained robots.
 One can understand the appeal of presenting the simulation in a mostly real environment. But the advantages of the VR experience are many. In particular, with the top-quality, retinal resolution light-field VR we hope to see in the future, the big advantage is you don't need to make the physical things look real. You will have synthetic bodies, but they only have to feel right, and only just where you touch them. They don't have to look right. In particular, they can have cables coming out of them connecting them to external computing and power. You don't see the cables, nor the other manipulators that are keeping the cables out of your way (even briefly unplugging them) as you and they move.
One can understand the appeal of presenting the simulation in a mostly real environment. But the advantages of the VR experience are many. In particular, with the top-quality, retinal resolution light-field VR we hope to see in the future, the big advantage is you don't need to make the physical things look real. You will have synthetic bodies, but they only have to feel right, and only just where you touch them. They don't have to look right. In particular, they can have cables coming out of them connecting them to external computing and power. You don't see the cables, nor the other manipulators that are keeping the cables out of your way (even briefly unplugging them) as you and they move.
This is important to get data to the devices -- they are not robots as their control logic is elsewhere, though we will call them robots -- but even more important for power. Perhaps the most science fictional thing about most TV robots is that they can run for days on internal power. That's actually very hard.
The VR has to be much better than we have today, but it's not as much of a leap as the robots in the show. It needs to be at full retinal resolution (though only in the spot your eyes are looking) and it needs to be able to simulate the "light field" which means making the light from different distances converge correctly so you focus your eyes at those distances. It has to be lightweight enough that you forget you have it on. It has to have an amazing frame-rate and accuracy, and we are years from that. It would be nice if it were also untethered, but the option is also open for a tether which is suspended from the ceiling and constantly moved by manipulators so you never feel its weight or encounter it with your arms. (That might include short disconnections.) However, a tracking laser combined with wireless power could also do the trick to give us full bandwidth and full power without weight.
It's probably not possible to let you touch the area around your eyes and not feel a headset, but add a little SF magic and it might be reduced to feeling like a pair of glasses.
The advantages of this are huge:
- You don't have to make anything look realistic, you just need to be able to render that in VR.
- You don't even have to build things that nobody will touch, or go to, including most backgrounds and scenery.
- You don't even need to keep rooms around, if you can quickly have machines put in the props when needed before a player enters the room.
- In many cases, instead of some physical objects, a very fast manipulator might be able to quickly place in your way textures and surfaces you are about to touch. For example, imagine if, instead of a wall, a machine with a few squares of wall surface quickly holds one out anywhere you're about to touch. Instead of a door there is just a robot arm holding a handle that moves as you push and turn it.
- Proven tricks in VR can get people to turn around without realizing it, letting you create vast virtual spaces in small physical ones. The spaces will be designed to match what the technology can do, of course.
- You will also control the audio and cancel sounds, so your behind-the-scenes manipulations don't need to be fully silent.
- You do it all with central computers, you don't try to fit it all inside a robot.
- You can change it all up any time.
In some cases, you need the player to "play along" and remember not to do things that would break the illusion. Don't try to run into that wall or swing from that light fixture. Most people would play along.
For a lot more money, you might some day be able to do something more like Westworld. That has its advantages too:
- Of course, the player is not wearing any gear, which will improve the reality of the experience. They can touch their faces and ears.
- Superb rendering and matching are not needed, nor the light field or anything else. You just need your robots to get past the uncanny valley
- You can use real settings (like a remote landscape for a western) though you may have a few anachronisms. (Planes flying overhead, houses in the distance.)
- The same transmitted power and laser tricks could work for the robots, but transmitting enough power to power a horse is a great deal more than enough to power a headset. All this must be kept fully hidden.
The latter experience will be made too, but it will be more static and cost a lot more money.
Yes, there will be sex
Warning: We're going to get a bit squicky here for some folks.
Westworld is on HBO, so of course there is sex, though mostly just a more advanced vision of the classic sex robot idea. I think that VR will change sex much sooner. In fact, there is already a small VR porn industry, and even some primitive haptic devices which tie into what's going on in the porn. I have not tried them but do not imagine them to be very sophisticated as yet, but that will change. Indeed, it will change to the point where porn of this sort becomes a substitute for prostitution, with some strong advantages over the real thing (including, of course, the questions of legality and exploitation of humans.)
Museums in ruins and old buildings will take on new life with Augmented Reality
Submitted by brad on Wed, 2016-09-07 15:09We're on the cusp of a new wave of virtual reality and augmented reality technology. The most exciting is probably the Magic Leap. I have yet to look through it, but friends who have describe it as hard to tell from actual physical objects in your environment. The Hololens (which I have looked through) is not that good, and has a very limited field of view, but it already shows good potential.
Topic:
Tags:
Fears confirmed on failure of fix to Hugo awards
Submitted by brad on Sat, 2016-02-13 15:31Last year, I wrote a few posts on the attack on Science Fiction's Hugo awards, concluding in the end that only human defence can counter human attack. A large fraction of the SF community felt that one could design an algorithm to reduce the effect of collusion, which in 2015 dominated the nomination system.
Topic:
Tags: